
Merkle Trees are a fundamental part of any blockchain system, and while it’s possible to create a blockchain without them, this could lead to significant scaling issues and limit the use of trustless blockchains to those with powerful, long-term computing devices. Thanks to Merkle Trees, however, it is possible to build Ethereum nodes that are compatible with all computers, tablets, smartphones, and even IoT devices, providing a secure and reliable platform for everyone.
So, how do Merkle Trees work? The simplest explanation is that they combine several different “chunks” of data into smaller buckets, and then take the hash of each cube. This process is repeated until you reach the root hash. This allows for an organized, trust-based authentication mechanism to be used to verify the accuracy of the data.
The most common form of Merkle Tree is the Binary Tree, which can be represented by the following diagram:
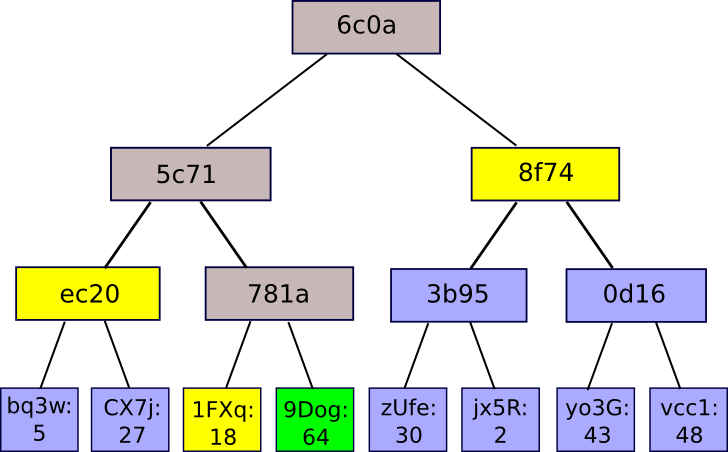
So, what are the benefits of using this hash algorithm? Well, instead of having to combine all of the data into one hash, you can use a regular hash algorithm. This allows for a “Merkle Proof” to be requested, which is a shard from the root hash of the tree and the “branch” comprising all hashes made on the path from shard-to-root. A test can then be performed to verify that the branch’s hash is consistent throughout and that the piece is in the right location.
The original application of Merkle Trees was for Bitcoin, as described and created by Satoshi Nakamoto in 2009. The Bitcoin blockchain uses Merkle Proofs to keep track of the transactions in each block. This concept has the advantage that, as Satoshi described it, “simplified payment verification” can be used. Instead of having to download the entire chain, a “thin client” can just download the block headers, which are made up of five items of 80-byte data each.
- A hash of the previous header
- a timestamp
- A mining difficulty value
- Nonce as proof you have worked
- A root hash of the transaction log for the block stored in a tree
A status report can be requested by thin clients to verify the status of transactions. A Merkle Proof can be used to show that a transaction took place in one of the Merkle Trees rooted in the block headers of the mainchain.
Unlocking the Potential of Merkling on Ethereum
Each block header on Ethereum includes more than just a Merkle tree – it includes three types of objects: proceedings, receipts (basically data pieces that show the “in effect” for each transaction), and expressions. Clients can create and verify verifiable answers to various types of questions with a sophisticated thin client protocol.
- Has this transaction been included in one block?
- Has this address sent me these instances of event type X (for example, a crowdfunding campaign that reaches its goal)?
- What is my current account balance?
- Has this transaction been included in a block, and what is the status of the transaction?
The Merkle Tree is a powerful tool that allows for the secure and efficient storage of data on the blockchain. Ethereum’s use of Merkle Trees enables the creation of a trustless and secure environment for users to interact with the blockchain.
Accounts on the Ethereum blockchain rely on data structures known as Merkle Trees to authenticate information that is not in the public domain. Merkle Binary Trees are excellent for this purpose, however, the Ethereum network requires a more complex tree structure known as the Merkle Patricia Tree. In this article, we will explore the basics of this tree and how it works.
Merkle Binary Trees are collections of fragments placed one after the other. They are wonderful because they don’t care how long it takes to grow. It is not possible to remove a tree from its roots after it has been established.
State in Ethereum consists of a key-value map, where the keys are addresses and the values are account statements. For example, take the genesis state. This is how the testnet looks.
The state tree makes things more complicated. It is important to preserve the past. The balance and nonce of accounts change frequently. Accounts are regularly created and keys are frequently added or deleted. Therefore, we need a data structure which allows us to quickly compute the root of a new tree after an insert, update, edit or delete operation.
Two secondary properties are highly desired: The Tree has a limited depth, even if an attacker creates transactions in order to make it as complex as possible. The Root of the Tree should only rely on the data, not the order in which the data are updated.
The Patricia Tree is, in simple terms, the closest thing to all these properties at once. It works by hard-coding the key in the “path” that takes the tree down. Each node can have up to 16 children and the path is determined by Hex Encoding. For example, the key “Doggy” Hex encoded “6 4 6 15 6 7” would start from the root, and work its way down to the sixth, and then the fourth, until it reached the end. Although there are optimizations that can make sparse trees more efficient, the core principle remains. All features can be described in more detail here.